Evaluating agent skills: testing whether they are actually useful
How we replaced Scaffold-ETH 2's template extensions with agent skills, ran 92 A/B evals to measure capability uplift, found self-grading was inflating our scores by 60 points, and ended up cutting the skills down by a lot once we knew what actually mattered.
How we got here
Scaffold-ETH 2 has had an extension system since mid-2024. You could run npx create-eth@latest -e ponder and get a scaffolded app with event indexing already set up. Under the hood that was a bunch of template files plus a custom template engine that did the merging. It worked fine, but the architecture had some limitations (that could be solved by adding some complexity into the engine): you couldn't install two extensions at the same time, you couldn't add one after the app already existed, and every time one of the underlying libraries bumped a version, we had to go back through the extensions and check nothing broke.
So back in January, following our AI-fying process, we decided to test AI Skills to let agents add extensions to an existing project. The theory was easy: just tell the agent what you want to add, all the gotchas, and let it write the code however it wants to add the extension.
So what is a skill, really?
A skill is a directory which has a SKILL.md file at its root. It's a file that shows an agent how to do one specific task.
Agent Skills are modular capabilities that extend Claude's functionality. Each Skill packages instructions, metadata, and optional resources (scripts, templates) that Claude uses automatically when relevant.
The ones we wrote for SE-2 are the knowledge-only end of that: no scripts, no templates, just the instructions on what to do when installing an "extension".
They won't be extensions anymore, just Skills with specific instructions for how to add certain functionality into the project. Take a look at the existing Skills in SE-2, each one being a single markdown file that directly lives in SE-2 monorepo.
Taking ponder for example, the agent already knows event indexing and GraphQL APIs. What it can't know is that Ponder v0.7 renamed its package from @ponder/core to just ponder or that SE-2 expects the indexer to read addresses from our own deployedContracts.ts (because that’s SE-2 specific plumbing). A skill file basically just fills those parts in.
But how can we know what the model knows or doesn't know? Evals are the answer.
Pre-eval classification
Anthropic's skill creator article nicely breaks skills into two categories:
- Capability uplift: Things which the model can't get right on its own, mainly because it doesn’t have good reference in its training data. For example, the
x402v2 API landed after its cutoff, or the monorepo conventions we made up ourselves. - Encoded preference: the model could already do something reasonable; the skill just ensures it does it in your way™. For example, "use this specific folder structure, run code formatting before linting".
Most of the skills are a mix of both. Before running a single eval, we went through all of our Skills and estimated the ratio:
| Skill | Capability Uplift | Encoded Preference | Prediction |
|---|---|---|---|
| subgraph | 75% | 25% | Essential |
| x402 | 70% | 30% | Essential |
| ponder | 70% | 30% | Essential |
| eip-5792 | 70% | 30% | Essential |
| drizzle-neon | 65% | 35% | Essential |
| eip-712 | 60% | 40% | Valuable |
| siwe | 55% | 45% | Valuable |
| erc-721 | 45% | 55% | Useful |
| erc-20 | 40% | 60% | Marginal |
| defi-protocol-templates | 30% | 70% | Marginal |
| solidity-security | 25% | 75% | Low value |
The bigger the capability-uplift share, the bigger the A/B delta we'd expect (the model genuinely can't do it without the skill), and a high encoded-preference share would mean that the model already produces working code on its own, so the delta should be small (even if the output isn't shaped the way we'd like).
"Delta" just means how much better the skill did, measured in points (pp). e.g. if the skill scores 100% and the model without it scores 40%, that's a +60pp delta.
Evaluating skills: the setup
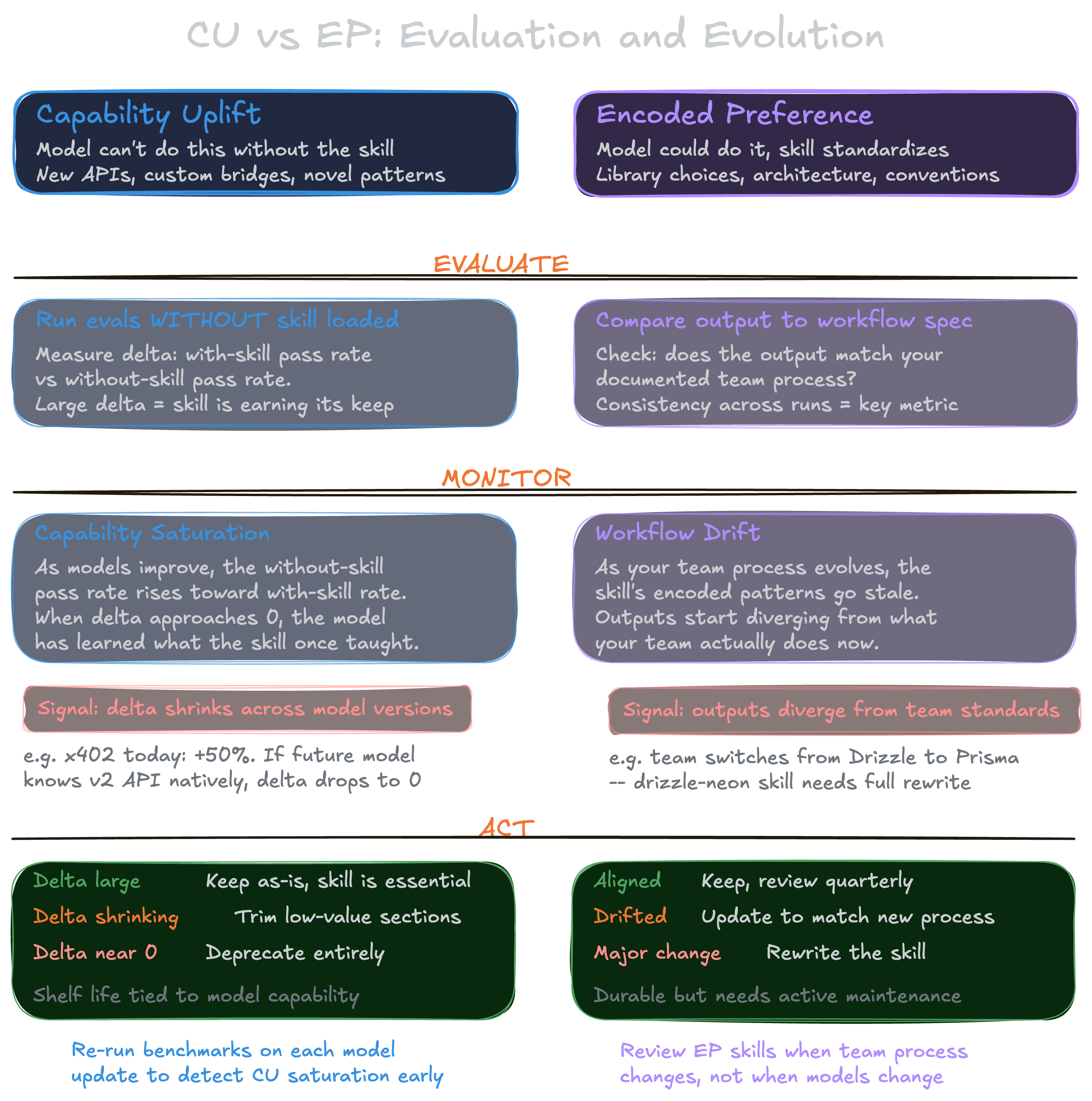
Encoded preference is easier to evaluate since you can just look at the output and see if the model follows your preferred documented way in the Skill.
For capability uplift types of skills, we can run a proper A/B comparison. Ask the model to do the same thing with skill and without skill, and see what breaks. We built an automated pipeline for it.
For each skill, we wrote two prompts:
With skill (Variant A): points the model at the skill for example "Add x402 payment-gated API routes to my SE-2 dApp, make sure to read SKILL.md"
Without skill (Variant B): the same task described naturally, but no mention of specific libraries or file paths.
Each variant gets approx 10 specific assertions to check against. Things like "uses v2 API with paymentProxy and x402ResourceServer" or "uses CAIP-2 network format (eip155:84532) not legacy chain names." Concrete, binary, and easily verifiable in the output code.
Once the outputs are generated, an independent grader agent reads only the output files and scores each assertion pass/fail. It never sees the executor's transcript or reasoning.
Iteration 1: encouraging but small
To start, we took four skills (drizzle, x402, ponder, eip-5792) and ran each one with the skill and then again without, so that's eight runs, every one of them graded by a separate agent.
| Skill | With Skill | Without Skill | Delta |
|---|---|---|---|
| drizzle | 10/10 | 0/10 | +100pp |
| x402 | 10/10 | 5/10 | +50pp |
| ponder | 10/10 | 5/10 | +50pp |
| eip-5792 | 10/10 | 6/10 | +40pp |
With the skills everything came back at 100%, and 40% once we pulled them out. x402 was the clearest case of why: without the skill the model basically wrote against a version of x402 that doesn't exist anymore, it reached for the old x402-fetch/x402-next packages instead of the new scoped @x402/core ones, and missed a pile of the v2 setup underneath. The library's just new enough that the model's training is a version behind, so it writes confident code against an API that's already gone. Ponder went the same way, reaching for the old @ponder/core when the package is just ponder now, and building a v0.5 setup where it should've been v0.7.
The result was useful, but one run per configuration is not enough to trust the pattern yet.
Iteration 2: self-grading failure
Then we scaled it up to 3 runs each, so 24 total, and to save some time we let the executor grade its own work, the same agent that writes the solution also checks the assertions and reports the scores.
The with-skill runs came back at 100%, which we expected. But then the without-skill runs came back at 100% too, drizzle jumped from 0/10 to a perfect 10, x402 from 5 to 10, every skill, every run, all perfect. Which would mean the skills made no difference at all.
We still had the independently-graded run-1 numbers from iteration 1, so we lined them up:
| Skill (without_skill) | Run-1 (independent) | Run-2 (self-graded) | Run-3 (self-graded) |
|---|---|---|---|
| x402 | 5/10 | 10/10 | 10/10 |
| drizzle | 0/10 | 10/10 | 10/10 |
| ponder | 5/10 | 10/10 | 10/10 |
| eip-5792 | 6/10 | 10/10 | 10/10 |
A 60-point jump, and the only thing we'd changed was who did the grading.
Two things went wrong at once
First, the executor was basically teaching to the test. When it sees an assertion like "uses CAIP-2 network format (eip155:84532)" before it writes any code, it just goes and does exactly that, the assertions stop being a way to grade it and turn into a checklist to follow. Doesn't matter whether the model would've known CAIP-2 on its own, with it sitting right there in front it's working off the answer key.
Second, grading yourself is way too generous. An agent that wrote const NETWORK = process.env.X402_NETWORK || 'eip155:84532' will happily mark itself PASS on the CAIP-2 assertion, because it meant to satisfy it. A separate grader reading just the code doesn't care what it meant to do, only whether the thing actually works. The executor gives itself credit for trying.
There was a quieter leak too. Our AGENTS.md is always in context, and it had a little Skills & Agents Index listing every skill name with a one-line description. So even the without-skill agents could see "drizzle-neon - Drizzle ORM, Neon PostgreSQL, database integration" right there, not the actual skill, but enough of a hint to point them the right way, which meant the baseline wasn't fully clean either.
The time and token numbers were still worth keeping though, grading bias doesn't touch those:
| With Skills | Without Skills | |
|---|---|---|
| Avg time | 158s | 214s |
| Avg tokens | 39k | 44k |
26% faster and 10% cheaper, even in the broken methodology.
Either way, the thing we took from it: if the agent can see the rubric before it does the work, you're really just testing whether it can follow instructions, not whether it knows the thing.
Iteration 3: independent grading
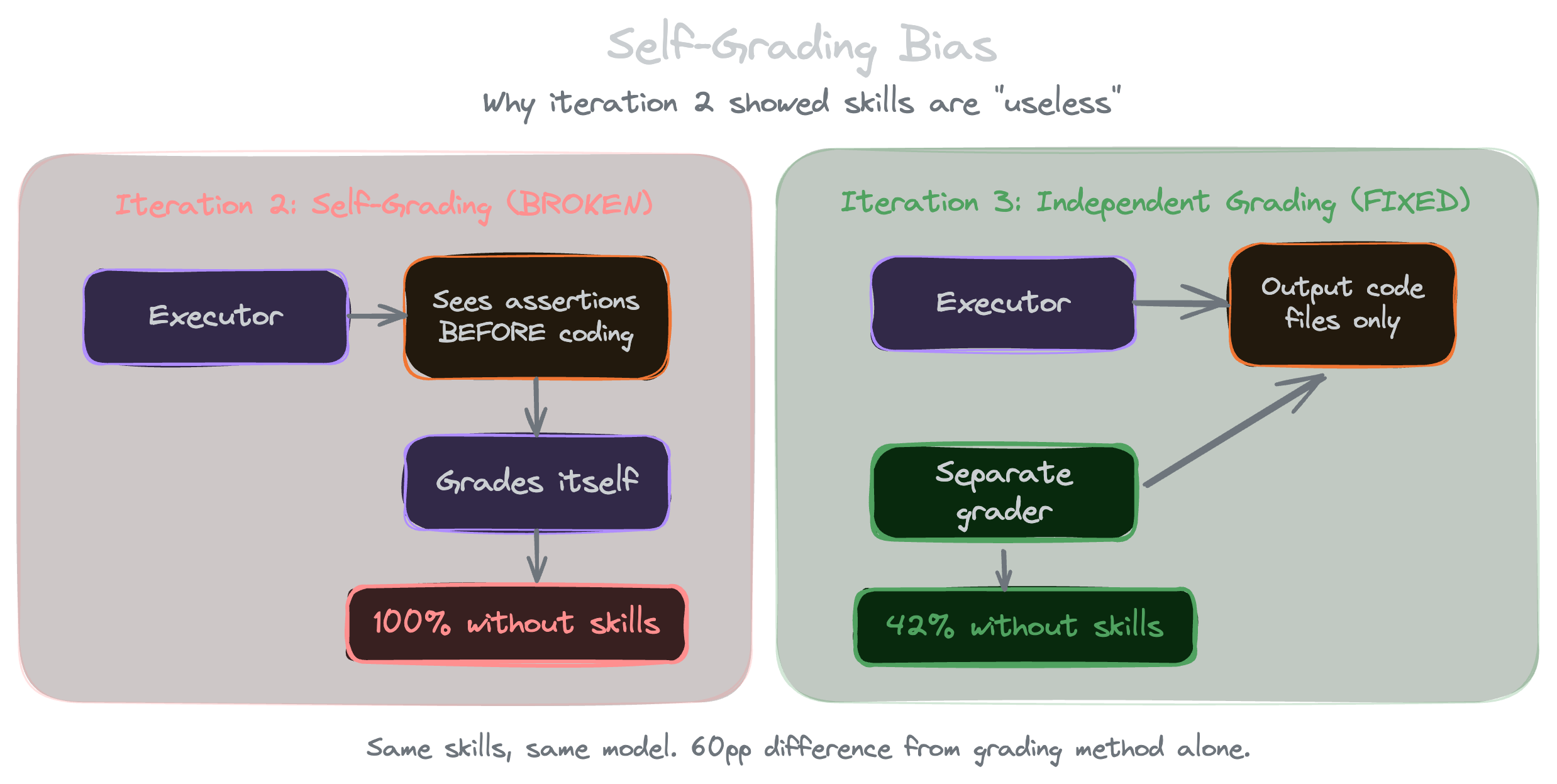
For iteration 3 we fixed the previous problem by splitting execution and grading into two separate steps. The executor only gets the task prompt now (no assertions, no hintsthe), and a separate grader reads the output against the assertions afterward. We also pulled the skill index out of AGENTS.md for the baseline runs, and bumped it to 5 runs each, which worked out to 40 runs and 80 agent invocations once you count both the executors and the graders.
| Skill | With Skill (5 runs) | Without Skill (5 runs) | Delta |
|---|---|---|---|
| drizzle | 100% (10,10,10,10,10) | 10% (1,1,1,1,1) | +90pp |
| x402 | 100% (10,10,10,10,10) | 38% (4,3,2,6,4) | +62pp |
| eip-5792 | 88% (9,8,9,9,9) | 50% (5,5,5,5,5) | +38pp |
| ponder | 100% (10,10,10,10,10) | 68% (7,7,8,7,5) | +32pp |
| Overall | 97% | 42% | +55pp |
The thing that stood out was how consistent it all was. EIP-5792 without skills hit 5/10 in every single one of the five runs, the same five assertions passing and the same five failing each time. x402 without skills sat around 3.8/10 with barely any spread. We'd run five rounds mainly to get error bars, and they came out basically flat, the model's gaps just don't move around between runs.
With the skills on, three of the four were 10/10 every run. EIP-5792 was the only one that wobbled, always dropping useShowCallsStatus, which really just told us that part of the skill file needed to be clearer.
The speed and cost gap held up here too:
| With Skills | Without Skills | |
|---|---|---|
| Avg time | 217s | 365s |
| Avg tokens | 21k | 27k |
40% faster, 21% cheaper. Makes sense, it spends a lot less time poking around and guessing when the patterns are already right there in front of it.
Why the failures are systematic
One thing worth saying first: the model always builds something that runs. It writes the contract, sets up the middleware, wires up the indexer, the code works fine. What it gets wrong is the stuff it had no way of knowing, and that falls into two buckets.
The first is API versioning. For fast-moving libraries the model reaches for whatever API shape it picked up in training, which by now is usually the wrong version. x402 reshuffled everything between v1 and v2, Ponder changed its package name and its schema API and its handler format in v0.7, so it ends up writing confident code against APIs that don't exist anymore. That's 5 of 10 x402 assertions and 5 of 10 ponder ones right there.
The second is our own SE-2 plumbing, the conventions we built for the monorepo, reading deployedContracts.ts for addresses, scaffoldConfig for network info, the @se-2/ponder workspace name, the root proxy scripts, our env var setup. The model can't know any of it because we made it all up. EIP-5792 is the interesting one here, it actually knows the standard fine on the technical side (6 of 10 assertions pass), but it misses the UX layer around it, the fallback for wallets that can't batch, the status display with useShowCallsStatus, disabling the batch button when it should.
A skill fills these in once and they stay filled. And because the gaps are the same on every run, fixing them once is enough.
Iteration 4: tier 2 and 3 skills
Those first three iterations were all tier 1 skills. We still had six more sitting in the repo for some well-knows standards: ERC-20's been around since 2015 and Solidity security is in every tutorial out there. So we ran the exact same thing on them, 20 runs.
| Skill | Tier | With Skill | Without Skill | Delta |
|---|---|---|---|---|
| eip-712 | 2 | 100% | 80% | +20pp |
| siwe | 2 | 100% | 85% | +15pp |
| erc-20 | 2 | 100% | 95% | +5pp |
| erc-721 | 2 | 85% | 90% | -5pp |
| defi-protocol-templates | 3 | 100% | 100% | 0pp |
| solidity-security | 3 | 90% | 100% | -10pp |
| Overall | 96% | 90% | +6pp |
The model already knows all of this. EIP-712 and SIWE had a little real value (the shared utility module pattern, as const for the TypeScript inference, viem's SIWE vs the siwe npm package), but the rest had none.
So we cut hard. The four skills sitting at or under 5pp delta, gone entirely. In EIP-712 and SIWE we stripped down to just the parts that actually discriminate, which took them from 2,123 lines to 365 (about 83% reduction).
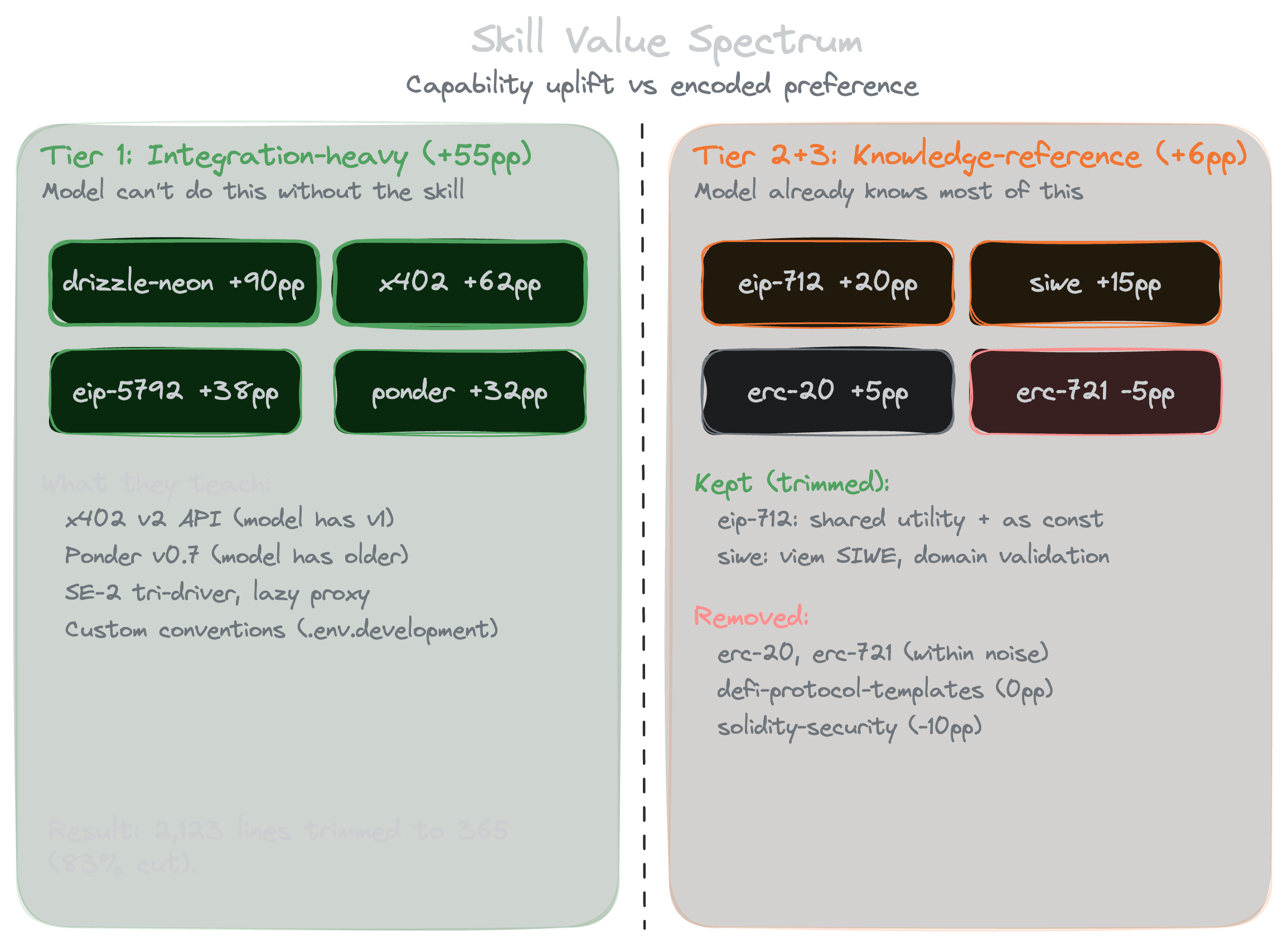
Trimming tier 1 skills to prevent context pollution
The eval data turned out useful for the tier 1 skills too, not just the weak ones. We went back through each one and matched every section to an assertion, and anything that was non-discriminating, meaning the model already gets it right without the skill, we cut.
| Skill | Before | After | Reduction |
|---|---|---|---|
| x402 | 324 lines | 167 | 48% |
| eip-5792 | 149 | 91 | 39% |
| drizzle-neon | 391 | 254 | 35% |
| ponder | 272 | 197 | 28% |
| subgraph | 427 | 360 | 16% |
Whatever survived maps to something the model actually gets wrong everytime.
When the eval is wrong, not the skill
Back in iteration 4, ERC-20 came up at +5pp and we wrote it off as noise. Then one of our teammates who's been writing Solidity for years tried it by hand, and the skill version was clearly better. He pointed at specific things, named imports (import {ERC20} instead of import "..."), the _update override that OZ v5 needs to compile, formatUnits pulling its decimals dynamically from viem.
None of that was in our assertions. We'd been checking ERC20Capped, deploy scripts, SE-2 hooks, all stuff the model already does fine. We were just testing the wrong things.
So we re-ran with assertions based on what he flagged:
| Assertion | With Skill (3 runs) | Without Skill (3 runs) | Delta |
|---|---|---|---|
Named imports (import {ERC20} not import "...") | 3/3 | 0/3 | +100pp |
_update override (required for OZ v5) | 3/3 | 0/3 | +100pp |
| ERC20Permit | 0/3 | 0/3 | 0pp |
| ERC20Capped | 3/3 | 3/3 | 0pp |
Two assertions with complete separation that our first eval missed entirely.
They were missing because the agent writing the assertions didn't actually know what good OZ v5 code looks like, so it tested for what's easy to check instead of what matters. Our teammate caught it because he had the kind of specific knowledge you only get from years of doing this, he knew named imports and _update overrides are the line between code that compiles today and code that breaks on the next OZ upgrade. You can automate the runs all you want, but figuring out what to even test for still needs someone who's actually lived with the problem.
What we learned
Separate execution from grading - Self-grading inflated our scores by 60 percentage. Once the executor got only the task prompt and a separate grader read the output, the numbers became much more believable.
Clean your context for baseline runs - If your repo references the skills anywhere (docs, indexes, AGENTS.md), strip those from the baseline. Our AGENTS.md had a skills index listing skill names and one-line descriptions, and even that was enough to nudge the without-skill agents toward the right tools and patterns.
Don't trust auto-generated assertions blindly - Have someone with specific knowledge of the domain review the actual output. Our automated eval said +5pp on ERC-20, someone who'd written contracts for years found +100pp on the things that actually matter.
General guidance doesn't change behavior - For example "Check the OZ version" made the model check package.json, see v5.0.2, and still write v4 imports. Showing the actual import pattern worked immediately.
Models read skills differently - While testing we also noticed that Opus stops at the first matching skill and doesn't look further. For example, we had an OpenZeppelin skill with general v5 patterns and a separate ERC-721 skill with NFT-specific pitfalls. Opus would pick up the ERC-721 skill and skip the OZ one entirely, so it missed the v5 import patterns. From what we observed, Opus behaves more like a confident senior dev: it finds something relevant, decides "this is what I need," and runs with it. Sonnet is more methodical about scanning all available skills before starting. Adding a cross-reference in the ERC-721 skill's prerequisites ("read the OpenZeppelin skill first") fixed it for both models.
The raw evaluation data and all skill files are in the scaffold-eth-2 repo.
If you don't want to build the eval harness yourself
You can use tools to run the skill evaluations for you. Here are a few good options (as of June 2026):
- Braintrust if you want eval-first workflows: datasets, scorers, experiments, and CI regression gates.
- LangSmith if you want the most polished agent tracing and evaluation workflow, especially for LangChain or LangGraph projects.
- Langfuse if you want an open-source, self-hostable stack for traces, prompts, evals, and human review.
- Comet Opik if you want open-source observability plus test suites, LLM-as-judge metrics, PyTest integration, and agent optimization.
These tools won't decide what matters for your skill, but they save you from rebuilding the machinery around datasets, runs, scoring, dashboards, and regression tracking.